
この記事の要点
- DeepSeek後の中国AI競争は、オープンかクローズドかではなく、モデルをどう配布し、どこで収益を回収するかに移っています。
- 安価に広く使われるモデルが増えるほど、クラウド、アプリ、業務導入側での競争が激しくなります。
- 企業はモデル名だけでなく、導入コスト、データ管理、業務連携、回収モデルまで含めてAI戦略を見る必要があります。
DeepSeekが壊したのは、性能ではなく前提だった
2025年1月、中国のDeepSeekが公開した`DeepSeek-R1`は、単に「中国から強い推論モデルが出た」という話では終わりませんでした。GitHubで公開された公式情報を見ると、`DeepSeek-R1`は総パラメータ6710億、アクティブ370億で、MITライセンスで商用利用可能です。しかも本体だけでなく、QwenやLlamaを土台にした蒸留モデルまで一緒に出した。この一手が効いたのは、性能比較表よりも、「強いモデルはAPIで借りるしかない」という業界の空気を壊したからです。
ここで起きた変化はとても人間的です。開発者は性能だけで製品を選ぶわけではありません。触れるか、試せるか、改造できるか、自分の環境に載せられるかで意思決定します。DeepSeekはその入り口を一気に下げました。だからインパクトはベンチマークの勝敗以上に大きかったのです。
なぜ百度も阿里巴巴も方針を変えたのか
面白いのは、その後の中国大手の動きです。2025年2月11日、百度の李彦宏はReutersの取材で「より賢いモデルを作るには、なお多くの計算資源が必要だ」と語っていました。つまりこの時点では、まだ「結局は資本力と計算資源がものを言う」という発想が強かった。
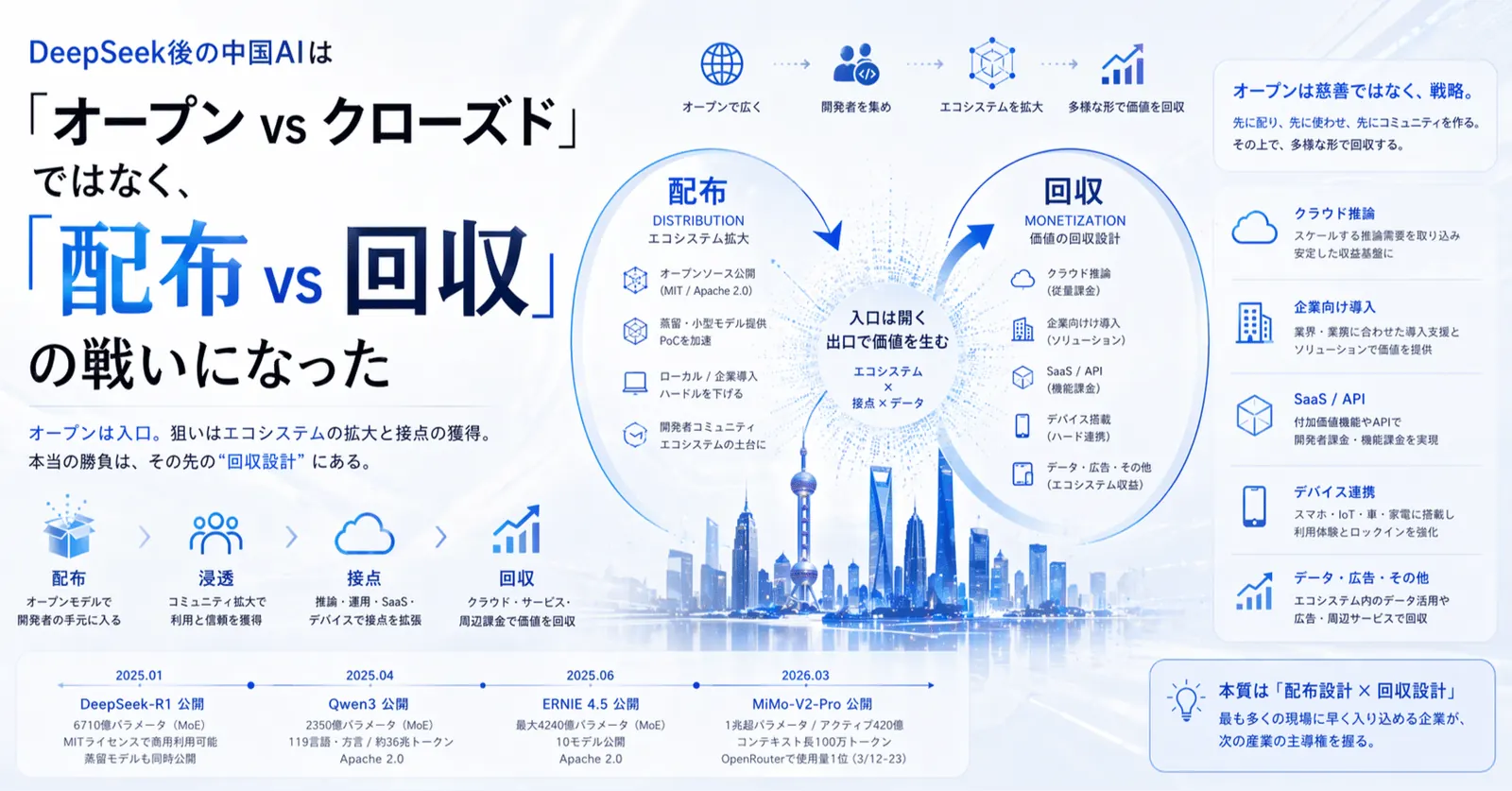
ところが流れは急速に変わります。2025年4月29日、阿里巴巴のQwenチームは`Qwen3`を公開し、2350億パラメータ中220億をアクティブ化するMoEモデルを含む複数モデルをApache 2.0で公開しました。公式ブログによれば、Qwen3は119言語・方言を支え、学習トークンは約36兆。さらに2025年6月30日には百度も`ERNIE 4.5`をオープンソース化し、最大4240億パラメータ、アクティブ470億の10モデルをApache 2.0で公開しています。
この変化を「中国企業も結局オープンソースに降参した」と読むと、本質を外します。実際には、オープンは慈善ではなく配布戦略です。開発者接点を握り、推論需要を呼び込み、クラウド、企業導入、デバイス搭載、周辺ツール課金へ回収する。その入口としてオープンが最適化された、という方が近い。
ここには具体的な利用シーンの違いがあります。以前なら、AI導入を考える企業はまず「どの海外APIを契約するか」を考えました。ところがDeepSeek以降は、「まず社内データで試す」「ローカルや専用環境に載せる」「小さい蒸留モデルでPoCを回す」という順番が現実的になった。中国企業はその変化を見て、最初から開発者の手元を取りに来たわけです。
この“手元に先に入る”という戦略は、スマホ時代の中国企業が得意だった勝ち方とも重なります。高機能を高価格で囲い込むのではなく、まず広く浸透させ、そこから運用と周辺サービスで強くなる。AIでも同じ構図が再現されていると考えると、最近の動きがかなり理解しやすくなります。
2026年に入って見えてきた、本当の主戦場
2026年になると、この流れはさらに明確になります。小米の2025年年次報告では、2026年3月に公開した`MiMo-V2-Pro`を「実世界のエージェント向け旗艦基盤モデル」と位置づけ、総パラメータ1兆超、アクティブ420億、コンテキスト長100万トークンと説明しています。同報告では、2026年3月12日から23日にかけてOpenRouterでトークン使用量1位だったとも述べています。
ここから見えるのは、中国AIの競争がもはや「誰のモデルが一番賢いか」だけではないということです。スマホ会社、小売会社、自動車会社まで含めて、自社のデバイス、自社の業務フロー、自社のユーザー接点にAIを埋め込める企業が強い。モデルは王様ではなく、接点を増幅するエンジンになりつつあります。
たとえば阿里巴巴のQwen3は、公式ブログでMCP対応を含むエージェント能力を強く打ち出しています。これは単なる研究成果の公開ではありません。「このモデルを使えば、ツール呼び出しや業務自動化までつなげやすいですよ」と開発者に伝えている。中国AI企業が競っているのは、モデル性能表の最上段よりも、“実装されやすさ”の方なのです。
独自視点は「オープンは無料化」ではなく「営業の前倒し」だということ
日本ではしばしば、オープンモデルの波を「価格破壊」とだけ捉えがちです。もちろん価格競争は起きています。しかし中国勢の本当の強みは、価格を下げたことより、営業・開発・導入の順番を入れ替えたことです。
従来は、まず大企業向けに営業し、PoCを回し、契約し、徐々に展開する流れでした。いまの中国勢は逆です。先に配る。先に使わせる。先にコミュニティを作る。その上で、推論、運用、デバイス、業務導入で回収する。言い換えると、オープンソースは技術戦略であると同時に、顧客獲得コストを下げる営業戦略でもあるのです。
「なるほど」と思うべき点はここです。オープンとクローズドは対立概念ではありません。入口を開き、出口で稼ぐ。中国AIの強い企業ほど、この二層構造を使い分けています。
日本企業と個人への学び・示唆
日本企業にとっての示唆ははっきりしています。いま基盤モデルをゼロから自前で作るかどうかで悩むより、「どのレイヤーで価値を取るか」を先に決める方が重要です。業界知識、社内データ、業務フロー、UI、導入支援、評価体制。このどこを握るのかが勝負になります。中国勢の動きは、その判断を先送りする余裕がなくなったことを示しています。
個人にとっての学びも同じです。これから差がつくのは、どのAIを知っているかより、どの仕事をAIに任せ、どこを人が持つかを設計できるかです。モデル名を追いかけるだけでは、すぐに陳腐化する。けれど、仕事の分解、評価基準の設計、再利用できるプロンプトやワークフローの整備は資産として残ります。
特に日本では、「高性能モデルを選べば勝てる」という発想がまだ残りがちです。しかし中国の最新動向を見ると、勝っているのは“最も賢いモデルを持つ会社”というより、“最も多くの現場に早く入り込める会社”です。これはAIに限りません。技術が成熟局面に入るほど、製品の優位より配布の優位が効きます。DeepSeek以降の中国AIは、その教科書のような展開になっています。
だからこそ、日本の経営や事業開発では「自社はどこで配れるのか」を問う必要があります。既存顧客基盤なのか、ハードウェアなのか、SI案件なのか、特定業界の運用ノウハウなのか。中国AIの動きは、技術選定より前に配布設計を考えるべきだと教えています。
この順番の逆転に気づけるかどうかで、AI投資の質はかなり変わります。モデルを見る前に、どう広げるかを考える。中国勢はすでにそのゲームを始めています。
DeepSeek後の中国AIを見ていると、技術の勝敗以上に、配り方と回収の設計が産業を動かしていることがよく分かります。日本が学ぶべきなのは「中国にも強いモデルがある」ではなく、「強いモデルをどう産業に接続しているか」です。そこにこそ、本当の差があります。
この記事に関するFAQ
AI・DX活用で最初に確認すべきことは何ですか?
対象市場、媒体特性、ユーザーが検索・比較する文脈、購入までの導線を分けて確認します。最初から大きく実行するより、反応を見ながら検証範囲を決めることが重要です。
日本企業がAI・DX活用に取り組むときの注意点は?
日本語の訴求を翻訳するだけでは不十分です。現地の生活文脈、価格感、口コミの信頼性、プラットフォームごとの表現ルールに合わせて設計する必要があります。
CrossLinkAsiaではどのような支援ができますか?
市場・SNS上の反応整理、KOL・クリエイター候補、販売導線、レポート設計まで、実行後に判断材料が残る形で支援します。